💪 Motivation
We highlight a key observation that drives our approach: within a convolutional layer, redundancy exists among the filters, as noted in various CNN compression studies, particularly in similarity-based filter pruning methods. Since all filters extract information from a common input, partially similar filters may produce partially similar output features. To enhance computational efficiency, the redundant computation of these similar parts should be avoided.
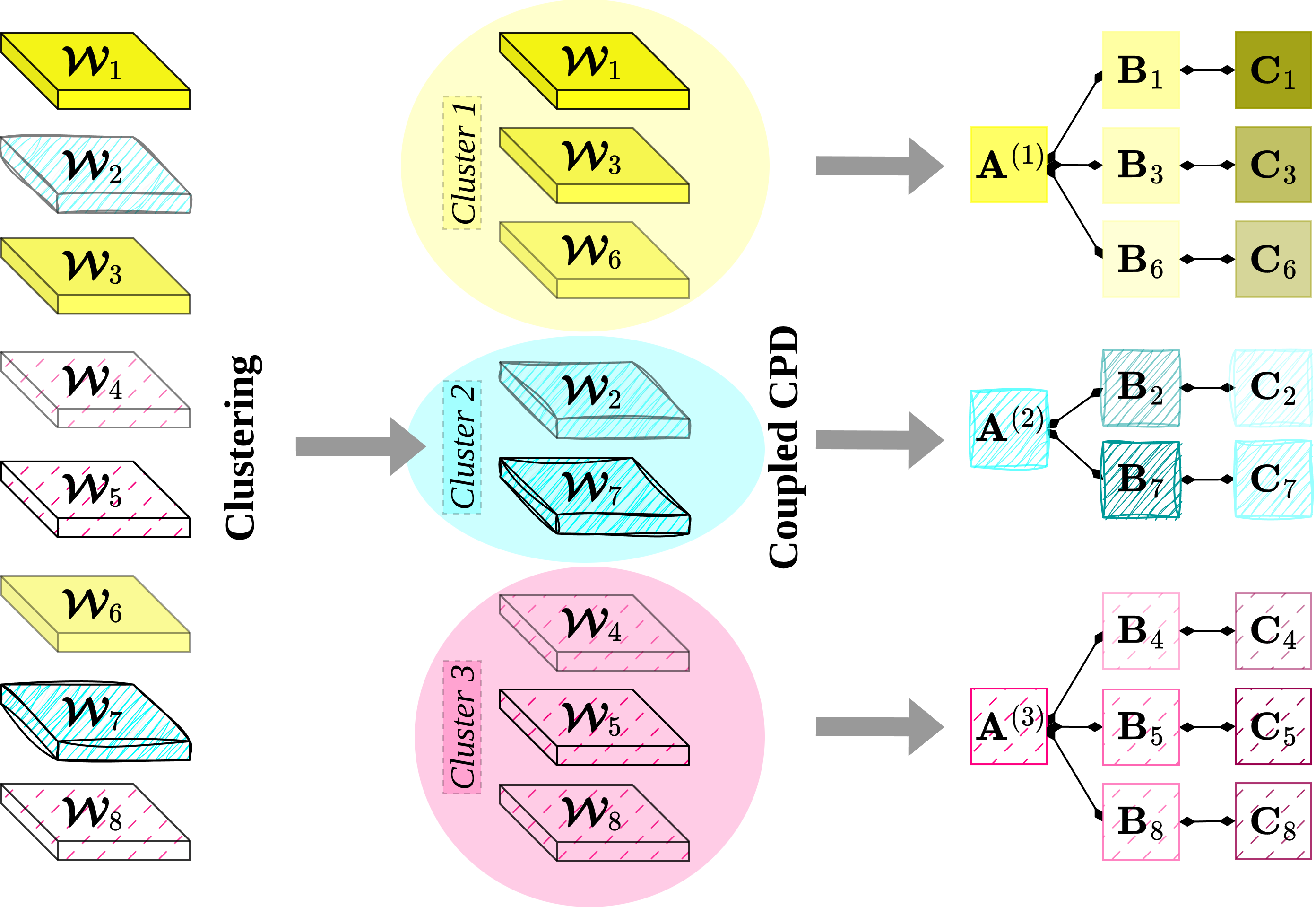
For example, in the top half of Figure 1, the filters \(\tens{W}_1\) and \(\tens{W}_3\) exhibit partial similarity, leading to their output feature maps \(\tens{O}_1\) and \(\tens{O}_3\) sharing a similar component (shown in blue) that is computed twice, causing redundant calculations. To avoid such duplicative computations and enhance efficiency, these filters can be jointly decomposed.
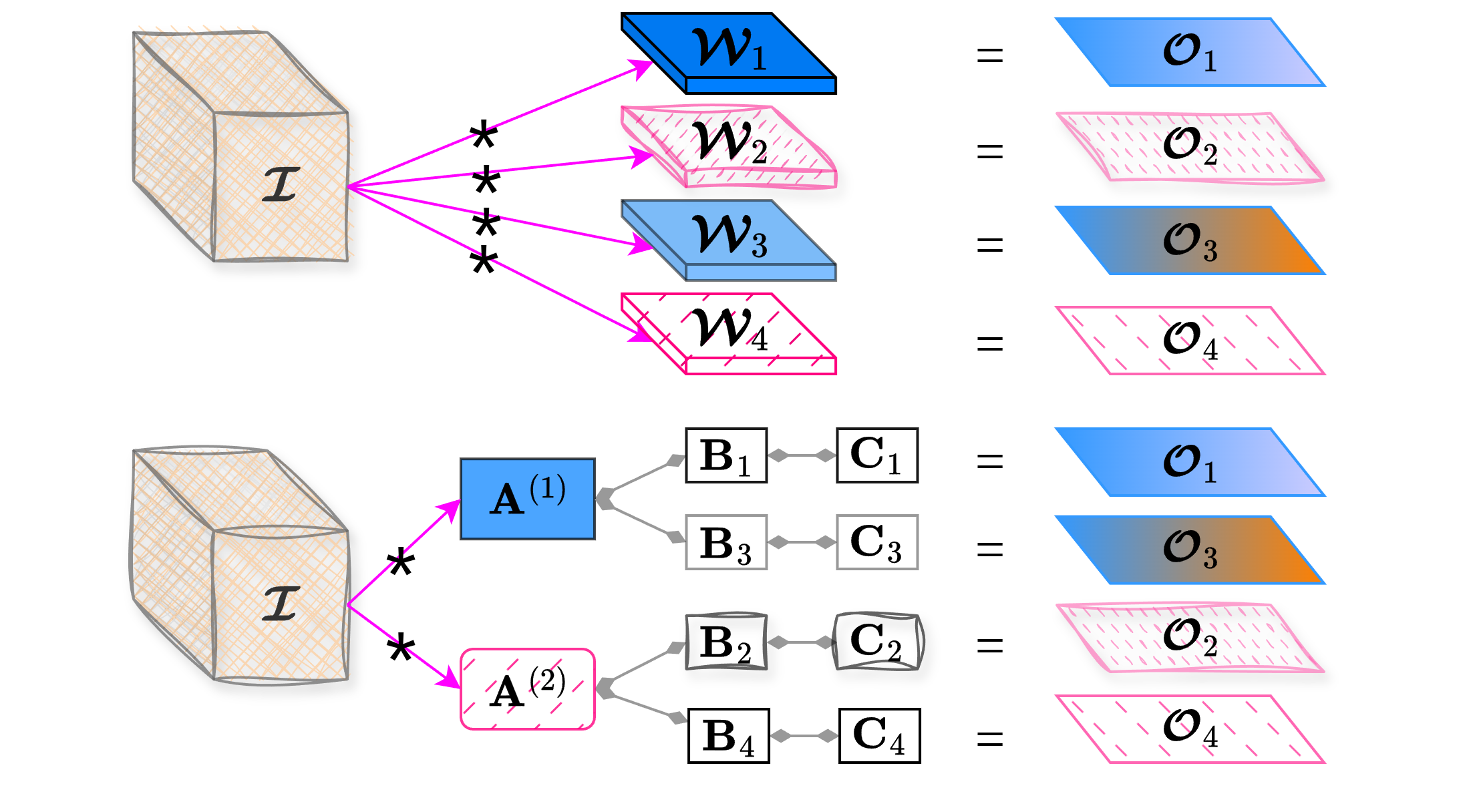
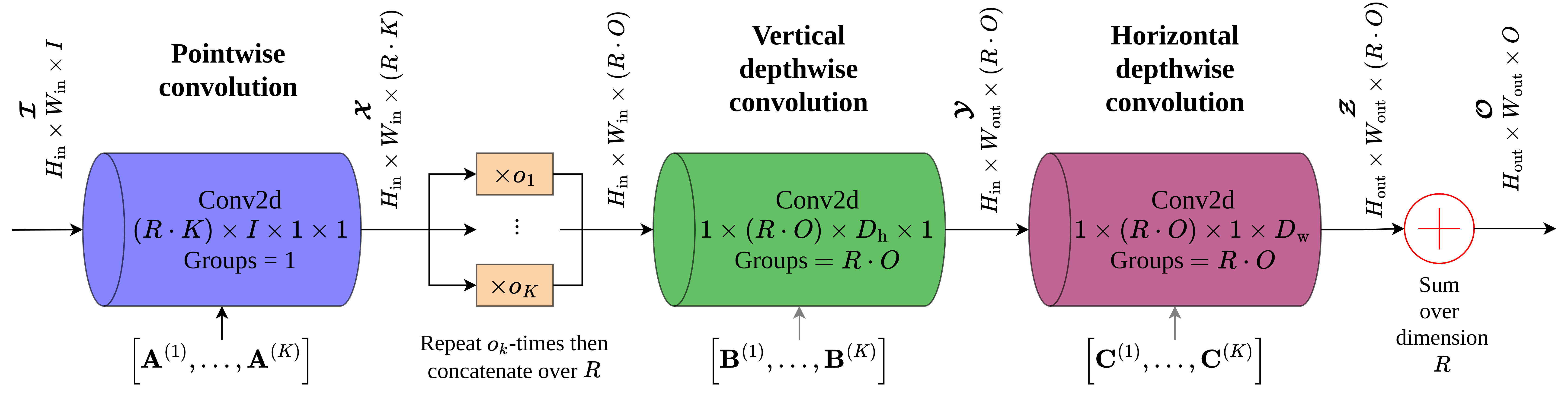
Building on these insights, we introduce the concept of coupled filters decomposition. In this scheme, multiple filters are jointly approximated using coupled tensor decompositions. To demonstrate the use of this method, we employ coupled CPD as a representative example due to its simplicity and efficiency, although our approach can be adapted to other decomposition techniques. Specifically, instead of decomposing each filter individually, we propose jointly factorizing them along a specific mode. After decomposition, the jointly decomposed filters share a common factor matrix in the selected mode while retaining their unique factor matrices in other modes.
This approach suggests that filters possess both common and particular characteristics. For instance, in the bottom of Figure 1, the two similar filters \(\tens{W}_1\) and \(\tens{W}_3\) are jointly factorized along the first mode, yielding a common factor matrix \(\matr{A}^{(1)}\) and different factor matrices in the other modes, namely matrices \(\matr{B}_1, \matr{C}_1\) and \(\matr{B}_3, \matr{C}_3\). Notably, since these filters share the same input tensor, the computation between the decomposed common factor and the input must only be performed once.